Рано или поздно появляется необходимость следить за состоянием оборудования компьютера. Самая “слабая” железка в нем, как известно, жесткий диск. Для мониторинга состояния жесткого диска используются данные S.M.A.R.T. — технологии оценки состояния и диагностики жесткого диска. По хорошему, S.M.A.R.T. — нечто вроде гадания на кофейной гуще — вроде бы предсказывает, но не всегда и сбывается. Тем не менее, наличие этой технологии в жестком диске все же лучше чем ее отсутствие — с ней, хоть и приблизительно, но все-таки можно узнать, что происходит с жестким диском. Когда дело касается не просто домашней файлопомойки с фильмами, а боевого сервера, на котором крутится нечто, приносящее деньги или доходы иного рода, размышления о точности SMART сходят на “нет”, и, для его мониторинга, на систему без разговоров “накатывается” соответствующий софт. О нем и поговорим.
Подробнее о S.M.A.R.T. вы можете посмотреть на википедии, я заострю внимание на ПО для Linux, как одной из наиболее популярных серверных ОС.
Для чтения данных S.M.A.R.T. в Linux (и, кстати, в BSD тоже) предусмотрен набор инструментов под названием smartmontools. В Ubuntu он доступен из стандартных репозиториев. Устанавливаем:
# aptitude install smartmontools
После установки необходимо узнать, доступен ли SMART на интересующем устройстве. Допустим, это /dev/sda:
# smartctl -i /dev/sda
Параметр -i выводит информацию по указанному вслед за ним устройству. В этой информации можно узнать, поддерживает ли S.M.A.R.T. устройство, и если да, то также можно узнать, включен S.M.A.R.T. или нет:

Для управления работой S.M.A.R.T. можно делать так:
# smartctl -s on /dev/sda
…для включения, и
# smartctl -s off /dev/sda
…для выключения.
Для вывода полной информации по устройству можно скомандовать так:
# smartctl -a /dev/sda
На выходе я получил много-много статистики по своему жесткому диску:
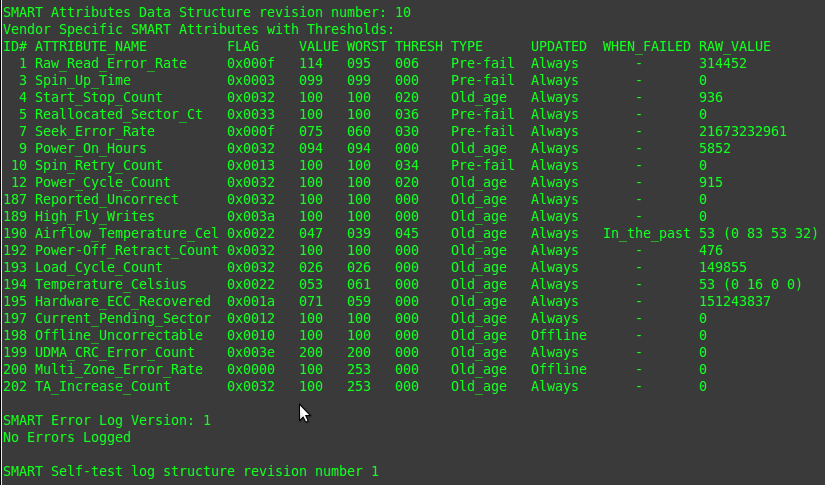
На самом деле её гораздо больше, я просто показал скриншот с самой “злободневной” информацией — эти значения могут дать вам представление о том, когда может сдохнуть жесткий диск. Однако, следует помнить о том, что выход некоторых значений за рамки заводских не всегда означает, что винту капец — единичные сбои случаются и с вполне исправным оборудованием. Так что рекомендую почитать поподробнее про саму технологию S.M.A.R.T. На деле, -a — параметр, который эквивалентен набору -H -i -c -A -l error -l selftest -l selective для ATA-дисков, и -H -i -A -l error -l selftest для SCSI-дисков (взято из man). Параметр -H выдает текущий статус устройства, составленный на основе различных тестов. -i — уже известный параметр, выдающий информацию об устройстве. -c — выдает только основные атрибуты S.M.A.R.T. — разные производители могут добавлять или убирать какие-либо атрибуты в S.M.A.R.T. -A — выдает информацию по специфическим для производителя атрибутам S.M.A.R.T. -l — выдает информацию из логов различных тестов. Для этого параметра необходимо указать значение — лог какого теста выводить.
Утилита smartctl хороша еще и тем, что при её помощи можно прогонять тесты жестких дисков. Однако, тут есть ограничение — единовременно можно прогонять только один тест. Для немедленного запуска теста есть параметр -t, после которого необходимо указать значение, характеризующее тест. Возможные значения:
offline;short;long;conveyance;select,<START_LBA>-<END_LBA>;select,<START_LBA>+<SIZE>.
Все виды тестов могут быть проведены при штатной работе устройства. Однако, и тут есть оговорки, и, поскольку ответственность за функционирование устройств и целостность хранящихся на них данных лежит только на вас, настоятельно рекомендую почитать man smartctl перед запуском тестов. Последние два теста (select — SMART Selective Self Test — тестирование определенного количества логических блоков устройства) принимают параметры — <START_LBA>, <END_LBA>, <SIZE>: соответственно адрес логического блока, с которого начинать, адрес логического блока, на котором заканчивать, количество блоков, которое тестировать. Использовать, например, так:
# smartctl -t offline -t select,0-100 /dev/sda
В этой команде я указал утилите прогнать offline-тест и selective-тест с нулевого по 100-й блоки. Разумеется, они будут прогнаны последовательно.
Если вы сталкиваетесь с ситуацией, когда находитесь на расстоянии от сервера или терминала, в котором можно посмотреть результаты тестов S.M.A.R.T., можно настроить уведомление об ошибках тестов по электронной почте. Это можно настроить при помощи файла smartd.conf . Подробнее о том, как это сделать, читайте man smartd.conf. Вкратце ситуация обстоит так — необходимо в этом конфиге создать правило, в соответствии с которым, по расписанию, будет запускаться определенный набор тестов и, в случае возникновения ошибок, на указанный e-mail будет отправляться сообщение.
Вот пример.
Открываю /etc/smartd.conf, пишу там (предположу, что у меня SCSI-диск):
/dev/sda -d scsi -m somemail@example.com -a -s L/../../1/02
Что здесь что: -d — тип диска (ata,scsi и т.д., подробнее в man smartd.conf), -m — отправка сообщения с ошибками по директивам -H, -l, -f, -C, -O. Эти директивы означают различные проверки, кое-что я уже описывал выше в абзаце про smartctl (они аналогичны), кое-что вы можете прочесть в man. -m использует стандартную утилиту mail для отправки письма, таким образом можно указать в качестве получателя root@localhost, и тогда письмо будет отправлено на учетную запись администратора, его можно будет посмотреть при помощи той же утилиты mail. -a — включает вышеописанные директивы в тест. И последнее — -s — параметр, при помощи которого можно указать конкретный тест для прогона в конкретное время. В качестве значения этот параметр принимает регулярку, общая структура ее такова — T/MM/DD/d/HH, где T — тип теста (в моем случае — L — Long self-test), MM — месяц (значения от 1 до 12, если цифра у числа меньше 10, перед ней ставится 0, иначе глюки неизбежны), DD — день (1 — 31, правила те же, что и для месяца), d — день недели (1 — 7, где 1 — понедельник, 7 — воскресенье), HH — час (1 — 24, правила те же, что и для месяца). Я написал на месте месяца и дня точки — это своего рода эквивалент * в crontab-файле. Что получилось: я поставил правило проводить тест Long self-test каждый понедельник в два часа ночи на SCSI-диске /dev/sda с отправкой сообщения на e-mail somemail@example.com в случае возникновения ошибок после проведения теста. Добавлю также, что -m позволяет отправлять сообщение на несколько адресов — их необходимо указывать через запятую. -m отправляет сообщение единожды (по умолчанию так настроено). В случае, если требуется задать правила отправки сообщений, используется параметр -M. в качестве значений принимает once, daily, diminishing, test, exec. Это, соответственно, однажды (по умолчанию), ежедневно, дополнительные сообщения (интервал в 1, 2, 4 и т. д. дня с момента обнаружения ошибки), немедленная отправка тестового сообщения на указанный ящик для проверки, указание пути к исполняемому файлу утилиты отправки почтовых сообщений (например, exec /bin/mail).
Вернусь к настройке. После конфигурирования smartd.conf открываю /etc/default/smartmontools и раскомментирую (комментарий #) строку
#start_smartd=yes
Делаю в консоли
# /etc/init.d/smartmontools start
Все, smartd запущен. Подчеркну, что все действия производятся из под root (я явно указал # перед текстом с командами для этого), чтобы не пришлось каждый раз набивать sudo перед командой, можно написать так:
$ sudo -i
Или, если у вас не установлена утилита sudo, но есть утилита su, вот так:
$ su
И ввести пароль. Таким образом вы откроете постоянный сеанс пользователя root внутри своего пользовательского.
Вот и все. Удачного вам мониторинга и количества бэдов, стремящегося к нулю ;)
Как сделать attribute auto save чтобы после ребута, сохранились параметры #smartctl -l scterc,0,0 /dev/sda
Приведите пожалуйста пример?
Не очень понял, что вы имеете в виду, спрашивая о сохранении параметров. Где вам нужно сохранять параметры? Что вы намерены делать с этим?
Таймауты на райдерном винте, нужно выставить в ноль. Я делаю так #smartctl -l scterc,0,0 /dev/sda они выставляются в ноль, только после ребута, Опять возвращаются к исходному. Говорят, что надо как-то сохранить их изменение attribute auto save. Только не могу найти примера. И ничего не получается.
У демона smartd есть конфигурационный файл, в котором можно эти параметры задавать. В Debian этот конфиг расположен в /etc/smartd.conf . Подробнее тут:
man smartd.conf
Т.е. Получается, что этот параметр нельзя отключить на вечно? Он должен после каждой перезагрузки, автоматически отключаться? Это значит, что отключив его на одном компе, на другом он опять окажется включенным?
Я не в курсе, может ли писать smartctl настройки для scterc напрямую в контроллер жестких дисков. Полагаю, что, либо smartctl не может сам по себе, либо у вас модель диска не предусматривает подобной настройки. В любом случае, я бы поискал на сайте производителя утилиту, при помощи которой можно было бы это сделать. Также, я нашел обсуждение необходимости отключения SCTERC, которое может быть полезным вам - http://forums.freenas.org/index.php?threads/new-4tb-seagate-nas-drive-st4000vn000-want-to-disable-erc-aka-tler.17389/ Опять же, ваш случай мне неизвестен, но “пищу для ума” этот топик, на мой взгляд, может дать.
Меня радует что WHER_FAILED пусто)) Но после таблицы 16 ошибок. :(
Спасибо за отличную статью! Для примера сможем проанализировать пример. Во вложении.
Рад был помочь :)
[…] Олег пишет: Тем не менее, наличие этой технологии в жестком диске все же лучше чем ее отсутствие – с ней, хоть и приблизительно, но все-таки можно узнать, что происходит с жестким диском. Когда дело касается не просто домашней … -m использует стандартную утилиту mail для отправки письма, таким образом можно указать в качестве получателя root@localhost, и тогда письмо будет отправлено на учетную запись администратора, его можно будет посмотреть при помощи той же утилиты mail. … […]
Рано или поздно появляется необходимость следить за состоянием оборудования компьютера. Самая “слабая” железка в нем, как известно, жесткий диск. Для мониторинга состояния жесткого диска используются данные S.M.A.R.T. – технологии оценки состояния и ди…